Exploring Multimodal Prompt for Visualization Authoring with Large Language Models
Zhen Wen1
Luoxuan Weng1
Yinghao Tang1
Runjin Zhang1
Yuxin Liu1
Bo Pan1
Minfeng Zhu2
Wei Chen1
1State Key Lab of CAD&CG, Zhejiang University 2Zhejiang University
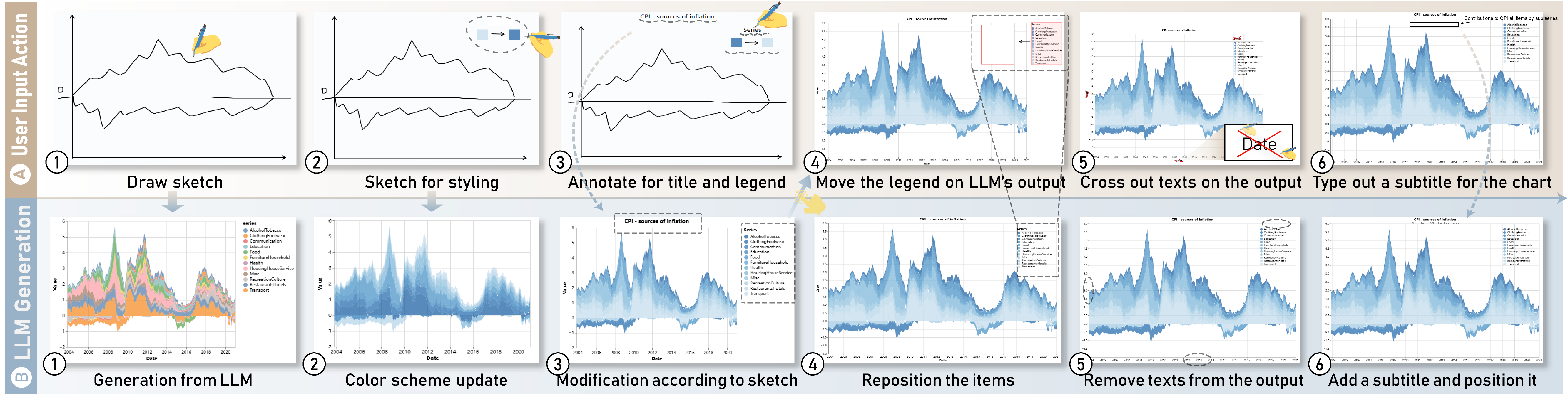
Multimodal prompt for visualization authoring with VisPilot. (A) The user can create visualizations by providing sketching, text annotations or directly manipulating existing visualizations. (B) VisPilot interprets the multimodal input and generates visualizations.
Abstract
Recent advances in large language models (LLMs) have shown great potential in automating the process of visualization authoring through simple natural language utterances. However, instructing LLMs using natural language is limited on precision and expressiveness for conveying visualization intent, leading to misinterpretation and time-consuming iterations. To address these limitations, we conduct an empirical study to understand how LLMs interpret ambiguous or incomplete text prompts in the context of visualization authoring, and the conditions making LLMs misinterpret user intent. Informed by the findings, we introduce visual prompts as a complementary input modality to text prompts, which help clarify user intent and improve LLMs' interpretation abilities. To explore the potential of multimodal prompting in visualization authoring, we design VisPilot, which enables users to easily create visualizations using multimodal prompts, including text, sketches, and direct manipulations on existing visualizations. Through two case studies and a controlled user study, we demonstrate that VisPilot provides a more intuitive way to create visualizations without affecting the overall task efficiency compared to text-only prompting approaches. Furthermore, we analyze the impact of text and visual prompts in different visualization tasks. Our findings highlight the importance of multimodal prompting in improving the usability of LLMs for visualization authoring. We discuss design implications for future visualization systems and provide insights into how multimodal prompts can enhance human-AI collaboration in creative visualization tasks.
The VisPilot System
The interface of VisPilot includes four components: (A) Chat Interface, (B) Free-drawing Canvas, (C) Design Panel, and (D) Authoring Flow.
Multimodal Prompt Framework
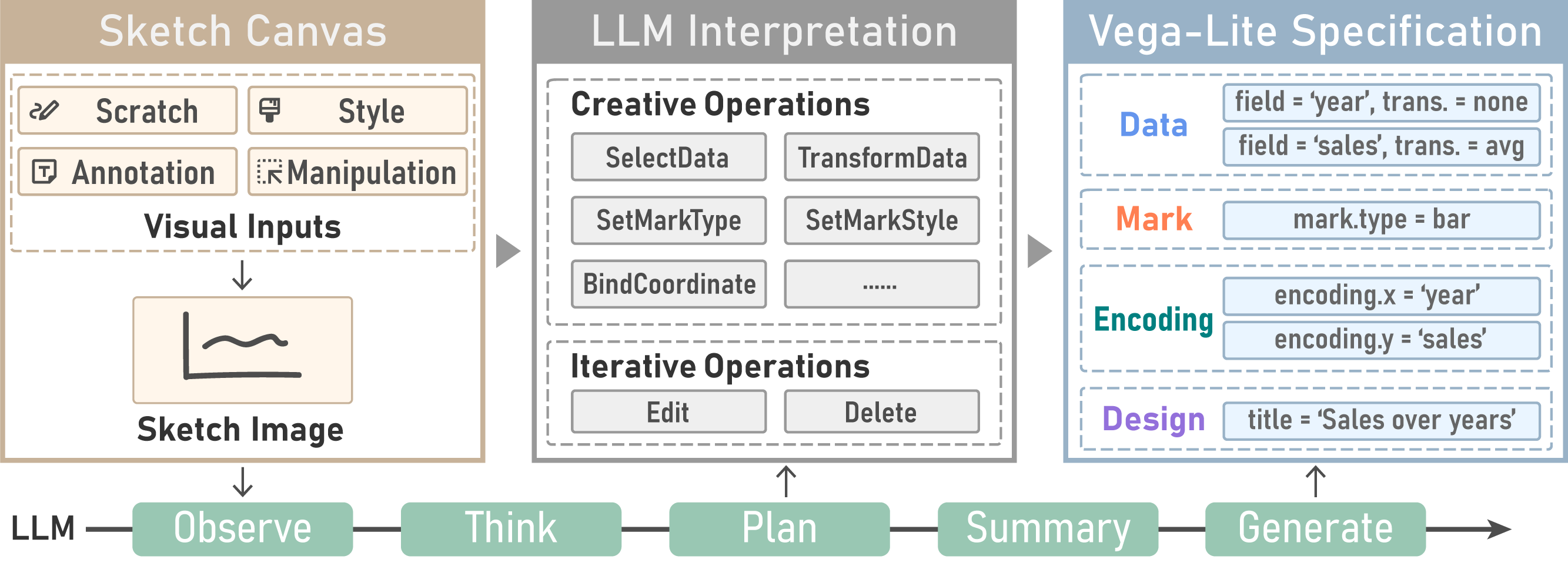
Our prompting framework instructs the LLM to interpret visual prompts to visualization specifications step by step.
Use Cases
Case 1 - Visualization Authoring
The video demonstrates the process of creating a sophisticated visualization using VisPilot (full video coming soon).
Case 2 - Data Exploration
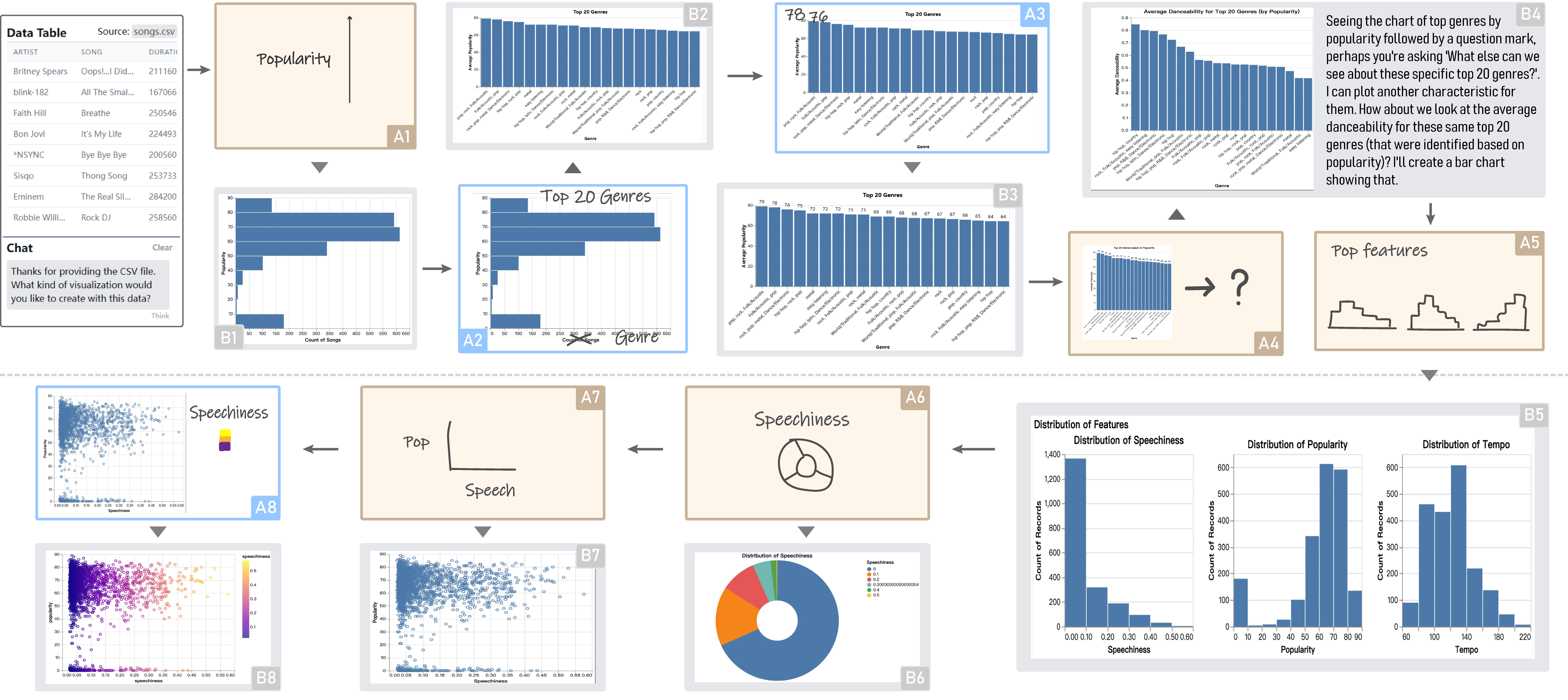
The use case of VisPilot for data exploration.
Research Contributions
- Empirical study on LLMs' interpretation of natural language prompts for visualization authoring
- Novel prompting framework for multimodal visualization authoring
- Interactive system for visualization authoring
- User study findings on multimodal visualization requests
Citation
@article{wen2025exploring,
title={Exploring Multimodal Prompt for Visualization Authoring with Large Language Models},
author={Zhen Wen and Luoxuan Weng and Yinghao Tang and Runjin Zhang and Yuxin Liu and Bo Pan and Minfeng Zhu and Wei Chen},
journal={arXiv preprint},
year={2025}
doi={10.48550/arXiv.2504.13700}
}